Multiprogramming- all you need to know
A brief description of multiprogramming on a single processor system




Photo by Christian Wiediger on Unsplash
Prerequisites
A CPU can have atmost one process running on it at any given time.
In this article we are considering a single general purpose processor system with no multicore or multiprocessor hardware.
In this article we are considering only heavy weight processes(no multithreading).
What is a process?
Simply put, a process is a program in execution. The codes we write and see are called programs; they reside in secondary storage like SSD or HDD and are also called Text Sections, and the actual runtime entity is called a process.
The CPU can only access the content of main memory and cannot access secondary storage content directly. So, content that is to be used by the CPU should be brought into the main memory. Whenever we run an executable file or an application, the program is loaded into the RAM, where it will have a temporary data section that holds the runtime data necessary for the program to run and is called a process stack.
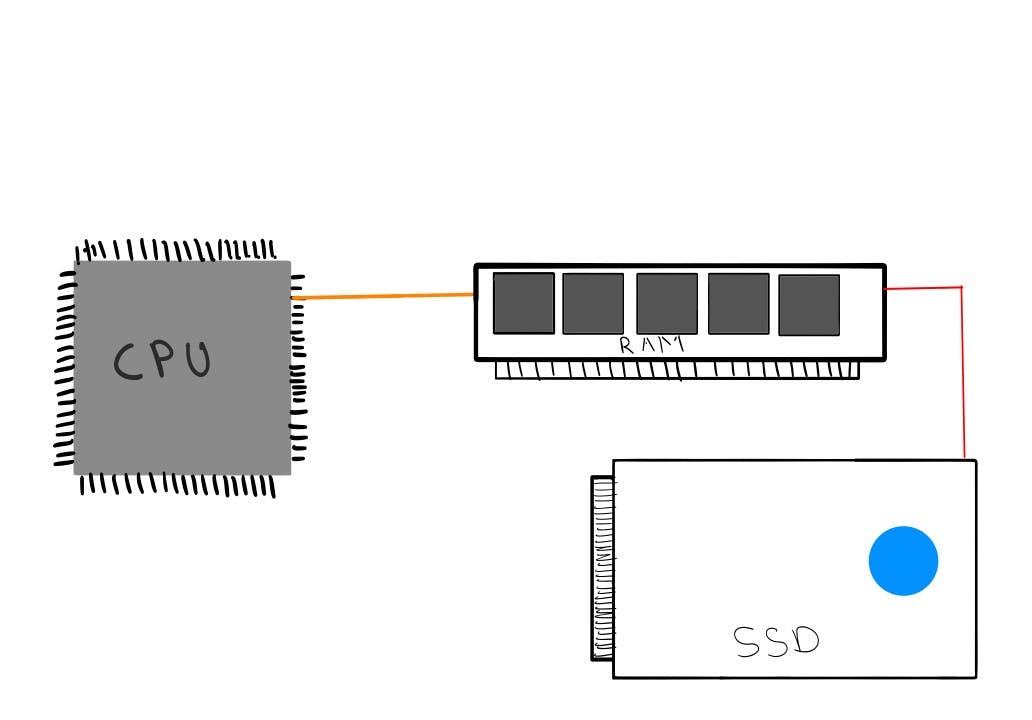
Image description
One program can have several processes. For example, when you open multiple browser windows, each one is a different process. These processes only have the text section in common and are completely independent of each other. From the OS point of view, these two processes are completely different despite them having the same underlying program.
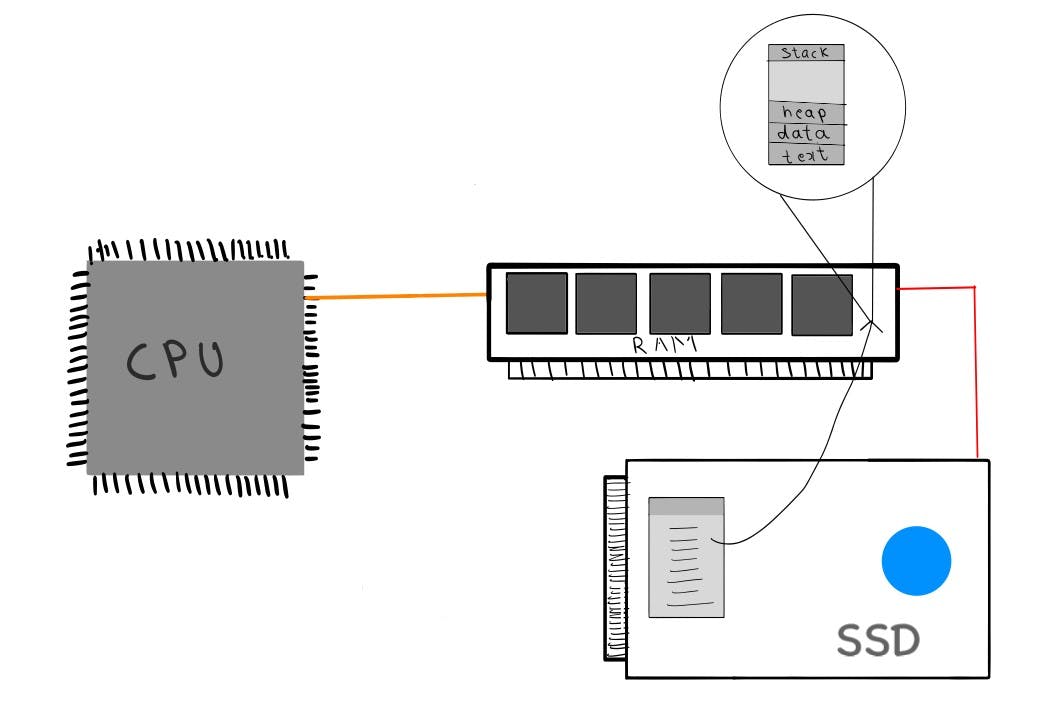
image description
What happens to processes?
So, the process in memory uses the CPU for execution and stores the results in the secondary storage. During this time, whenever there is a need to do something else, like waiting for a keyboard stroke or for a mouse click, the process execution will be halted, waiting for the event to happen. Normally from a human time scale, this may seem like nothing, but with modern CPUs having gigahertz scale clock rates, it is a huge waste of CPU time being idle.
Solving the problem of Idle CPU
Now that we know when one process is waiting for a long event to happen, the CPU remains idle. So, the solution is to have multiple programs in the memory, and whenever the CPU is idle, swap out the process with a different one in memory.This creates an illusion of parallel execution but is in fact just concurrent execution with various processes rapidly switching onto the CPU.
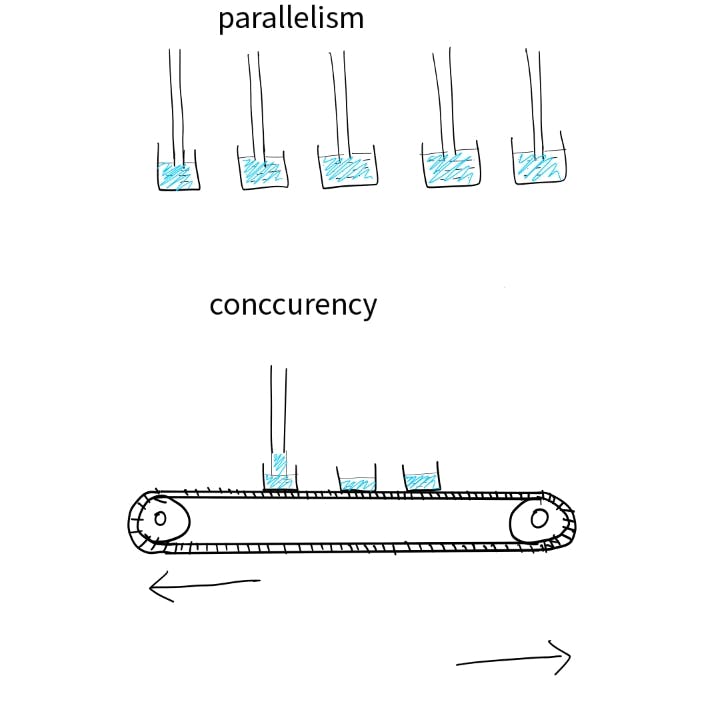
image description
This is called multiprogramming. The aim of multiprogramming is to have some process on the CPU all the time, maximizing its utilization. The challenge now is to decide which process in the memory the CPU should be allocated. for this purpose, we have various schedulers executing their scheduling algorithms. Almost all modern operating systems provide support for multiprogramming.
Different systems have different types of scheduling algorithms depending on the purpose. On mainframe systems maximizing utilization takes priority, in real-time systems maximizing interactivity takes priority, in time-shared systems, well you know time sharing takes priority.
Process life-cycle
Now that we have seen that several processes exist in memory let us see the specifics. Every process in the memory is in one of the following states:-
running
waiting
ready
There will be a queue for each of the waiting and ready states. The queue is typically a linked list of Process Control Blocks, A.K.A PCB (more on this later). The appropriate schedulers will select one of the processes in the queue and allocate its requested resource. In the case of a ready queue, the resource would be a CPU, and in waiting queue the resource would be an I/O device or a storage device.
A process during its execution will be switching among these states and finally terminates or will be suspended.
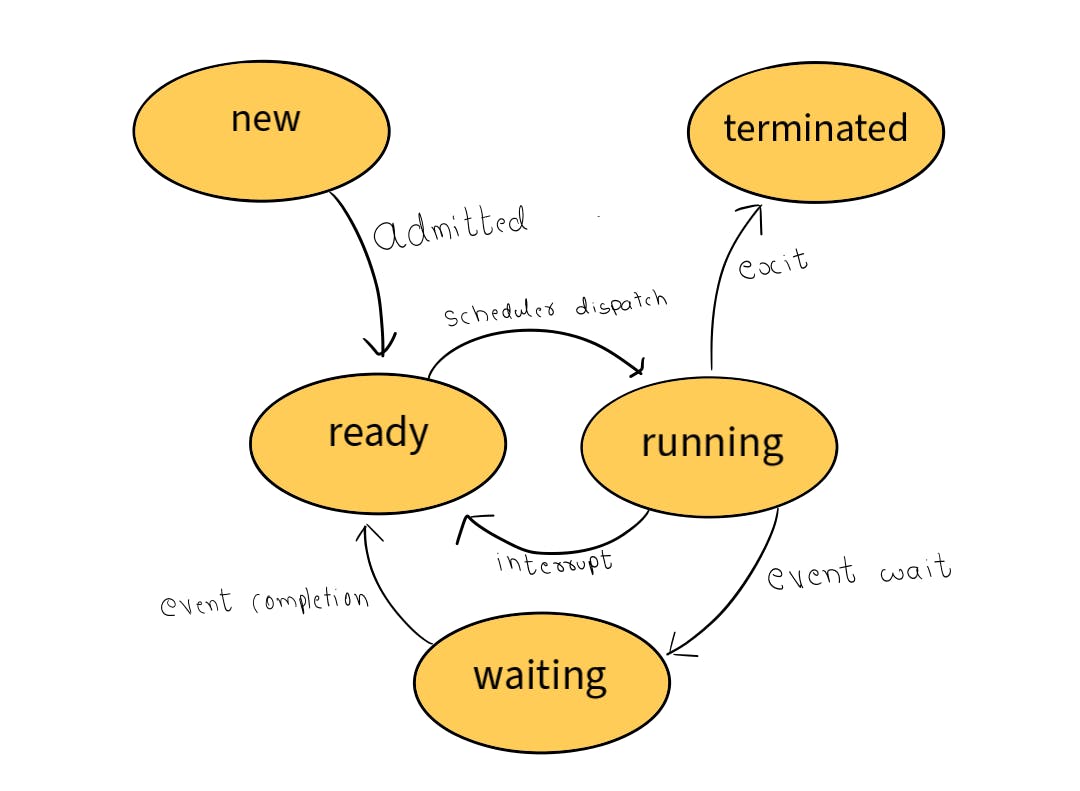
Image description
Schedulers
At each level, there will be different schedulers implementing a scheduling algorithm.
The short-term scheduler or the CPU scheduler ,present at the ready queue level, selects one of the processes in the ready queue and allocates the CPU for it.
The medium-term scheduler, present at the memory level, swaps out process blocks in and out of memory and selects "processes" from the secondary storage. So, what actually happens is that the entire process stack is swapped out of the main memory due to memory constraints and brought back in whenever there is a requirement. When several such processes exist, there should be a decision making algorithm to select a subset of them to be in the memory.
The long-term scheduler, present at the memory level, is mostly used in batch Operating systems, and it selects a set of jobs(programs) from the secondary storage and brings them into the main memory. It is deprecated and no longer used in modern operating systems and is replaced by the medium-term scheduler.
What happens when processes switch?
Scheduling decisions take place in one of the following situations:-
A process switches from running state to a waiting state
A process switches from running state to ready state
A process switches from waiting state to ready sate
A process terminates.
in case of 1 the CPU becomes idle and a process from the ready queue should be selected. The CPU registers and cache memory will be populated by the processing being executed so far, and all this information needs to be saved so that when the process resumes its execution later, it will appear as if the execution never stopped for the process.
So, a state save is performed during which register and cache memory are saved and the process is swapped out of the CPU. The new process scheduled to run will proceed and populate the registers and cache. Eventually when this process also terminates or enters a waiting state, state restore of one of the earlier process is done during which the registers and cache are repopulated with the saved process data.
This is known as a context switch, and a considerable amount of time will be spent during which the CPU will remain idle. A context switch is performed by a process called "Dispatcher" and the time from the stopping of one process to the starting of another process is known as dispatch latency. Studies are going on to reduce context switch time as much as possible as it is pure overhead.
The context switch that happens in cases 2 and 3 is called "preemption", where the preempting process will take over the CPU despite another process already running on it upon request.
If that is not the case ( 1 and 4), it is called non-preemptive, wherein during the execution of one process, it will continue to do so until it enters a waiting state or it terminates even if a different process requests CPU time. Preemption is a complex topic as it involves a lot of complex matters to deal with, such as coherency and context switch overheads.
What next?
Now that we have seen how multiprogramming happens in a single processor system, the next article will focus on multicore and multiprocessor systems.
PS:- I used Adobe Fresco on iPad for the illustrations above